
A Motivating Game
Let’s play a game. I’m going to think of an integer, and now you have to guess the first digit. Is there any way you can do better than randomly choosing a digit 1-9? For psychological reasons, my number is probably going to start with 7 (it is my favorite digit), but let’s suppose I was choosing purely randomly.
For a hint, you might ask what is the range of integers that I’m choosing from. If I’m only choosing from the range 500 to 600, for example, your best option is a lot clearer. But all I’m willing to tell you is that I am choosing from 0 to n (exclusive), where n > 1. Quickly, you could figure out that if n is a power of 10 (i.e. 10, 100, or 1,000), then you can’t do any better than random guessing. Every digit appears as the first digit precisely 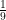
You might be getting an inkling that the lower digits are your best bet for winning the game, and this is true. We can illustrate this by graphing the probability that 1 will be the first digit in a game as a function of n for that game. For comparison, we can make the same graph for the highest digit – 9. The red dashed line represents what the probability would be if every digit occurred with equal frequency (aka 0.11). Notice that the probability of 1 being the first digit is always 
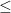


We can see the trend more clearly by graphing frequency (of being the first digit) vs. n for all 9 digits. I used a log scaling on the x axis to make the graph more evenly spaced (since dips/peaks occur at powers of 10).

So now you know that you should guess 1, but how likely are you to be correct using this strategy? Basically, we want to determine the average value of each of these curves. The standard strategy for doing this is to integrate the curve over a finite interval and then divide by the length of the interval. Using the interval 1 to 1ooo, we can find that the (approximate) probabilities for each digit are as shown below.

These values can maybe be thought of as the “frequency” that the digits show up as first digits in the infinite sequence of natural numbers. However, when I tried to do further research as to whether these probabilities actually show up anywhere in the real world, I found that there was an altogether different “first digit law” that shows up seemingly everywhere.
Benford’s Law
Benford’s law is named for physicist Frank Benford, who wrote a paper on it in 1938. It gives a distribution for first digits that applies to many different data sets and mathematical sequences. It states that the probability that some digit d will be the first digit is 

The distribution dictated by Benford’s Law, similar to the first digit frequency we found for the natural numbers, indicates that lower first digits {1,2,3} are significantly more likely to occur than higher ones {7,8,9}. However, the distributions are not quite the same.

The reason Benford’s Law has a name, while our first distribution is stuck with the anonymous moniker “integration method”, is that the Benford distribution actually shows up in tons of data sets. Population data, stock prices, lengths of rivers, physical constants, the Fibonacci numbers. A fun exercise is to find some numerical data set (at least 100 entries) and check how closely the first digit distribution follows Benford. I’ve been on a Mathematica kick recently, so I chose GDP values from the 233 countries included in the CountryData tag. From the graph below, you can see the actual digit distribution pretty much follows what we would expect from Benford.

Explaining Benford’s Law with a Circular Slide Rule
So this begs the question: Why do so many datasets have first digits which follow this neat mathematical distribution? To answer this question, we can use the fact that the first digit of a number is encoded in it’s mantissa. What is a mantissa? The mantissa of a number n is the part after the decimal point of 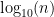


The mantissa is unaffected by the addition of trailing zeros – so the mantissa of 2830 or 283,000,000 will also be 0.45179. Adding a trailing zero means you have to multiply by 10, meaning the characteristic of the logarithm will increase by 1, but the mantissa won’t change.
But what does it mean that the first digit is encoded in the mantissa? Well, basically, all numbers that start with 1 will have a mantissa between m(1) and m(2). Similarly, all numbers that start with 5 will have a mantissa that lies between m(5) and m(6). The intuitive reason for this is because the characteristic of the logarithm “absorbs” the less significant digits of the number – leaving the mantissa to carry the information about the more significant digits. So if two numbers share their most significant digit, their mantissae will be similar.
Now imagine a circular slide rule, which multiplies numbers by mechanically adding their logarithms. It utilizes the property that 
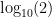
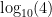


Looking at the circular slide rule makes Benford’s Law a bit more intuitive. We can imagine it as a roulette wheel where multiplying several numbers is a “spin”. If we keep spinning the roulette wheel, we will land between 1 and 2 roughly 30% of the time, which is how often we expect to see 1 as a first digit according to Benford’s Law. More precisely, we expect to have 1 as a first digit when we land on the segment from 

This analysis also gives us a better idea of what kinds of data sets will align with Benford. For example, exponential sequences are generated by repeated multiplication by a constant. As long as the mantissa of this constant doesn’t evenly divide the circle (like if the mantissa is irrational), this process will eventually cover the entire circle, implying the sequence will obey Benford’s Law. Since the irrationals greatly outnumber the rationals, nearly every exponential sequence will be Benford (this is a bit of a simplification, see here for a more complete explanation). An obvious exception to this “rule” is the sequence generated by multiplying by 10 every term. This explains why Benford’s Law applies to datasets that were created by exponential growth, like population data.

However, many other phenomena follow Benford’s Law as well, and this is most likely because they too can be thought of as being created by a series of multiplications. For example, stock prices typically scale by a constant each day. Or various variables (such as population, resources, and productivity) multiply together to create a nation’s GDP. There are no strict guidelines that govern whether a data set will follow Benford’s law, but the circular slide rule explanation gives us a clue.
Deriving Benford’s law with Scale Invariance
Another fascinating thing about the Benford distribution is that it is scale invariant. This means that if you take a data set that follows Benford’s Law and then multiply it by a constant, this data will still follow Benford’s Law. Since unit conversion is done by multiplying by a constant, this means a Benford dataset is Benford regardless of what the units are. This makes a sort of sense, units are an arbitrary choice and shouldn’t affect a digit distribution.
Benford’s distribution is actually the only distribution that has this property of scale invariance. We can see this pretty clearly by imagining the circular slide rule again. Pick a point on the outer rim to represent a number (it’s first digit will be determined by what segment it is in). To multiply this number by a constant we move it a fixed distance along the outer rim (the fixed distance is the 
Now, imagine instead of picking one point along the rim, we chose a distribution of points. Multiplying the distribution by a constant involves taking all those points and moving them all the same fixed distance along the rim. This is equivalent to rotating the disk around its center by some angle 
To illustrate this, imagine a distribution that is non-uniform and has an increased density of points in some region on the rim of the disk. Now when we rotate the disk, the increased density of points will now be in another region. Therefore, the distribution has changed and is consequently not scale invariant. We described above how a uniform distribution of points along the rim of the circular slide rule implies Benford’s Law. So we know that it is the only possible scale invariant distribution.

We can see an example of the scale invariance of Benford’s Law using the GDP data set from earlier. The data we graphed earlier was in US Dollars per year, but scale invariance implies that it shouldn’t change if we convert into other forms of currency such as euros or pesos. When we try it, we can see that the distribution remains quite similar.

Benford’s Law is also the only distribution law that is base-invariant. This means that in base b, the probability that some digit d will be the first digit is 
Generalizing to More Digits
Calling Benford’s Law the “first-digit law” is a bit of a misnomer. It also specifies a distribution function for the second, third, and nth digit in a number. The first digit simply exhibits the furthest “skew” from the uniform distribution that we intuitively expect. The generalization to multiple digits is quite easy to conceive if we keep our ideas about mantissae in mind. Earlier we talked about how all numbers that start with 3 will have a mantissa between m(3) and m(4). Similarly, all numbers that start with 13 (such as 13,000 or 139) will have a mantissa between m(13) and m(14).
We will assume that mantissas are evenly distributed, which is equivalent to saying numbers are uniformly distributed around our circular slide rule. So the probability of a number starting with 13 is 


Of course, we can use the same procedure to generalize to 3+ digits and the distributions get flatter and flatter. Notice that instead of the (less general) formula, we used the assumption that the mantissae of numbers are uniformly distributed. In fact, this is exactly how mathematician Simon Newcomb described the same phenomena (actually earlier than Benford did!).
The law of probability of the occurrence of numbers is such that all mantissae of their logarithms are equally probable.
Newcomb, American Journal of Mathematics (1881)
Applications
Benford’s Law has a fairly famous application in fraud detection. Most genuine financial data, such as tax returns or invoices, generally follows Benford’s law. However, fabricated data is unlikely to follow the law, due to humans natural bias towards uniform distributions. There tend to be too many numbers starting with 7,8, and 9 for example. Even if someone uses a random number generator, the distribution will be uniform rather than Benford because of the lack of exponential or multiplicative growth.
If a data set that should theoretically be Benford is not, it can raise a red flag for someone doing an audit. This cannot conclusively prove or disprove fraud, since often there are other factors causing an anomalous distribution, like a spending cap. However, it can raise suspicion for further investigation. In a 1993 case where Wayne James Nelson was accused of trying to defraud the state of Arizona of $2 million, check amounts that didn’t follow Benford’s Law was the initial clue that something wasn’t right.
Reflection
I’m sure Benford’s Law is of particular interest to forensic accountants (and I suppose, tax evading criminals trying to come up with some random numbers). As someone who belongs to neither of those groups (or at least doesn’t admit to it), I thought what was most interesting was to consider what data sets should conform to Benford’s Law.
The natural numbers don’t appear to, as I discussed at the beginning of this post. So Benford’s Law says something about real-world data, not just about numbers. The circular slide rule explanation exposes that exponential sequences and other multiplicative sequences should follow Benford’s Law. But does that apply to data sets of physical constants, or heights of mountains, or the masses of celestial bodies? All of these examples, and many more, have been observationally shown to follow Benford’s Law. Maybe the real discovery that Benford and Newcomb made isn’t just about digits, but about how multiplicative and exponential growth is inherent to so many unexpected corners of our universe.