2-Coloring Doodles
I was playing around with MS Paint recently and I ended up with a drawing that will probably look familiar to anyone who has ever idly messed around with MS Paint.

In addition to the nostalgia of remembering digital doodles from elementary school, I had another thought about this drawing. I wondered if it could always be colored with 2 colors “correctly” – such that colors only touched at corners (like a checkerboard). When I colored the drawings in using the Fill tool, the correct coloring naturally falls into place, but it is not entirely clear that should always happen. I could imagine a situation where it becomes unavoidable to color two adjacent regions with the same color (or to add a third color).
In fact, you will always be able to correctly color a pattern like this with 2 colors, and we can show it with a very simple inductive proof. We will induct on the number of lines in our pattern. If there is only one line splitting the plane, we (of course) can color the pattern by simply making one side black and one side white. So the “base case” works.
Now suppose we have a pattern made up of n lines and we have successfully 2-colored it. When we add another line, we can split the plane into 2 regions based on this line and arbitrarily designate one to be red and the other to be green. Leave the green region colored as it is, and invert the coloring in the red region (make black regions white and white regions black). Now along the new line no adjacent regions will have the same color, because one side’s coloring was inverted.

So we generated a successful 2-coloring for n+1 lines from a coloring for n lines. Therefore (by induction), we can 2-color a pattern made up of any integer number of lines splitting the plane.
With a little work (try it!), we can generalize this result to patterns made up of closed shapes, curved lines, and lines that overlap themselves, like those shown below.


The condition on 2-colorable “doodles” is that the lines can only overlap at single points. This means that no two lines can share a segment of non-zero length. In addition, only two lines can intersect at any single point.
Moving onto Maps
Of course, the logical next question is: what if we made drawings (like those in coloring books) that did allow lines to have overlapping segments? How many colors would we need to color such a pattern “correctly” a.k.a. such that no two adjacent regions have the same color? We will call these patterns “maps” because cartographers usually try to preserve this property to prevent confusion between neighboring countries, states, provinces, or regions.

A map of the United Stated colored with 7 colors. No adjacent states share a color. In this map, countries that touch at a corner also don’t share a color, but this is not a constraint for our purposes.
Source: Washington Post

By drawing a couple pictures, we can see that at minimum, we need 4 colors. This is because we can draw a map with 4 regions such that every region shares a side with all 3 of the others. This map clearly requires 4 colors. However, I was not able to draw a map with 5 regions such that every region shared a side with all 4 others.
But this by itself does not imply that all maps can be colored with 4 colors. It is easy to imagine a more intricate map where not being able to use the same color in two adjacent regions would eventually force a fifth or even sixth color.

Maps → Graphs
This problem can be simplified somewhat by taking maps, which contain weird shapes of varying sizes, and translating them into “graphs” which only contain nodes and connecting edges. Every region will get a node, and if two regions share a side, then their nodes will be connected with an edge. This removes a lot of the complexity of the individual shapes involved in the maps, but preserves all the information we need to color them (because, based on the edges, we know which nodes cannot be the same color).

All possible maps will lead to “planar” graphs, meaning that they can be drawn without the lines crossing (curved lines are allowed). Non-planar configurations do not correspond to valid maps, which makes a kind of sense if you consider the edges in a configuration to be analogous to regions.
Proof of the 6-Color theorem
Since the 4-color theorem is rather difficult to prove, let us start with the substantially easier (and weaker) 6-color theorem: no map requires more than 6 colors to ensure that no two adjacent regions have the same color.
We can apply theorems about planar graphs in order to prove the 6-colorability of all maps. One theorem is that every planar graph with 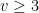




We will use proof by contradiction, so assume that every vertex in a graph connects to 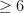
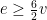
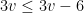
We can use proof by contradiction again to prove the 6-color theorem. Imagine there are some graphs that are not 6-colorable. If this is true, then there must be some minimal graph that is not 6-colorable. This graph – called a minimal criminal for “breaking the law” of 6-colorability – has the property that removing any edge will render it 6-colorable.
Suppose that this minimal criminal has a vertex A connected to 5 or fewer edges (it must, as we proved above). Let’s remove A and the edges connecting to it from our map entirely. The remaining graph has fewer edges than our minimal criminal, and therefore must be 6-colorable. So let us 6-color it. Now when we add A back into our map, there has to be a color (out of the six we are using) that is leftover, since A only connects to a maximum of 5 other countries. So we color A that leftover color and now our supposed “minimal criminal” is 6-colored. So no minimal criminal can exist and all graphs are 6-colorable.

Attempting to Prove the 4-Color Theorem: A Proof of the 5-Color Theorem
The first attempted proof of the 4-color theorem appeared in 1879 by Alfred Kempe. The proof was similar to our proof of the 6-color theorem, but the cases where the node that was removed had 4 or 5 vertices had to be examined in more detail. Kempe came up with a method that involved exchanging sequences of alternating colors called Kempe chains. In order, to give you a better understanding of Kempe chains, I will explain how they can be used to prove the 5-color theorem.
From our proof of the 6-color theorem, we can realize that the only case that does not directly generalize to 5-colors is the case where the vertex we remove has 5 edges and connects to 5 differently colored vertices (since there will be no leftover color to use on the central vertex). So consider a vertex connected to 5 other vertices each with a distinct color. The method of Kempe chains (illustrated below) then allows for the 5 nodes surrounding our vertex to be colored with 4 colors, leaving the fifth for the central vertex.

Kempe cleverly used the method of Kempe chains to prove the 4-color theorem – or so he and the mathematical community thought. The proof appeared valid for 11 years until Percy John Heawood published a paper pointing out that in a particular subcase, Kempe’s method will not yield a 4-coloring (see here for more detail). Kempe tried to revise his proof, but was unable to do so. Note: The proof of the 5-color theorem using Kempe chains that we showed above is still valid.
Appel and Hakken’s Computer Assisted Proof
After Heawood refuted Kempe’s proof, mathematicians continued to try to prove (or disprove!) the 4-color theorem for over 80 years. Finally, in 1976, Kenneth Appel and Wolfgang Hakken published a paper called “Every Planar Map is Four Colorable”. Their eventual successful method ended up being similar to the proofs we discussed for the 6-color theorem and the 5-color theorem, only substantially more complicated.
The idea of the proof is to first come up with a set of configurations (which are subgraphs) such that every planar graph must contain at least one. This is called an unavoidable set. Then, it must be proved that every configuration in the set is reducible. This means that we can remove it from the larger graph, recolor the surrounding nodes with only 4 colors, and then reinsert the configuration colored with only 4 colors as well.
While this sounds complex due to the terminology, this is exactly what we did for the proof of the 5 and 6-color theorems. Our unavoidable set of configurations contained a single vertex with 1, 2, 3, 4, and 5 connecting edges.

Then we showed that each of these 5 configurations was reducible if we had 6-colors (just using common sense) or if we had 5-colors (using the method of Kempe chains). This proved there could be no minimal counterexample to the theorems, and therefore that the theorems were true.
Now the question becomes, how did Appel and Hakken come up with an unavoidable set of configurations where every element was reducible? They used something called the method of discharging. This involves treating a planar graph as an electrical network with charge assigned to the vertices such that the charges sum to a small positive value. Then the charges are redistributed in the graph via a set of discharging rules, which preserve the sum of the charges. The discharging rules are designed so that only certain subgraphs can “hold” positive charge. Since the charge is conserved, these subgraphs form a set of unavoidable configurations for the graph as a whole.
Appel and Hakken used a significant amount of trial and error to come up with discharging rules that resulted in a completely reducible set of unavoidable configurations. They prioritized having the unavoidable configurations be small, with a maximum ring size (the number of nodes in the boundary of the configuration) of 14. Their eventual discharging algorithm was simple enough to be implemented by hand (but still had 300+ rules) and yielded a set of 1,936 unavoidable configurations.
Each of these 1,936 unavoidable configurations had to be individually checked by a computer for reducibility. This took over 1,000 hours of computer time. And then, the 4-color theorem had finally been proven.
Appel and Hakken’s proof was the subject of some controversy because its extensive use of computational strength meant that it was not human-verifiable. Mathematicians worried that there could be some error in the software used to check for reducibility, which would render the proof invalid. Even the “human-verifiable” piece of the proof (the discharging procedure) was extremely complicated (400 pages of calculations!) and therefore impractical to actually check in its entirety. However, other software was later used to confirm the complete reducibility of the unavoidable set generated by Appel and Hakken. Smaller completely reducible unavoidable sets (as small as 633 configurations) have also been generated and checked. So the 4-color theorem has been proven beyond a doubt.

Still, a level of dissatisfaction about the 4-color theorem remains in the mathematical community. There is lingering doubt that what Appel and Hakken did constitutes a “real” proof, since no human could ever completely understand every computation involved (there simply isn’t enough time in a single person’s life). Part of the problem is that the proof is rather ugly to the human eye: nearly 2,000 cases that have to be each checked individually?! The proofs of mathematical theorems are so often beautiful places of insight. By comparison, the complicated piece of calculation that is Appel and Hakken’s proof appears woefully inelegant.
However, there is something compelling about the fact that this simply-stated theorem remains unprovable without computer aid. Perhaps it suggests that we are reaching a point in mathematics where the complexity of our theorems and conjectures exceeds our personal computational abilities. And isn’t it exciting that we now have the tools (amazingly powerful computers) to take that next step? Computer assisted proofs are here to stay – examples include sphere packing, optimal Rubik’s cube solving, and coloring the Pythagorean triples – and our understanding of what a “proof” is will likely expand to accomodate.
Puzzles 🙂
It can be a rather fun time to try to “disprove” the 4-color theorem on your own by drawing some maps that are difficult to 4-color. People on StackExchange (1, 2, 3) thought the following maps were counterexamples to the 4-color theorem, can you color them successfully? (Note: You can copy the images into MS Paint and use the Fill Tool to color)



If those weren’t enough of a challenge, try 4-coloring this puzzle. (Disclaimer: It took me 4 tries before I could do it)

If you enjoy doing these kinds of puzzles (I certainly did) then check out the FourColor app (for iOS) which has a dozen or so more.
You might wonder if there is a general algorithm for 4-coloring a map, especially given the difficulty in proving that such a coloring even exists. Surprisingly there is, and it is even quadratic (a.k.a. pretty decent) in time-complexity! However, if you are given a planar graph, it is NP-complete to decide whether it is 3-colorable (not doable in polynomial time).
It seems appropriate that we can now use computer algorithms to 4-color maps, given that the (somewhat controversial) proof of their 4-colorability relies on the brute computing power of the modern era.

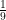 of the time (giving you an 11% chance of guessing correctly). But what if n was, for example, 3,000? The first thousand numbers have an even distribution of digits, but the next thousand (from 1,000 to 1,999) all start with one, and the rest (from 2,000 to 2,999) all start with two. Clearly, 1 or 2 is your optimal guess in this game (where n = 3,000).
of the time (giving you an 11% chance of guessing correctly). But what if n was, for example, 3,000? The first thousand numbers have an even distribution of digits, but the next thousand (from 1,000 to 1,999) all start with one, and the rest (from 2,000 to 2,999) all start with two. Clearly, 1 or 2 is your optimal guess in this game (where n = 3,000). 0.11 while the probability of 9 being the first digit is always
0.11 while the probability of 9 being the first digit is always 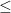 0.11.
0.11. 



 .
. 


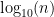 . We’ll use m(n) to denote the mantissa of n. For example,
. We’ll use m(n) to denote the mantissa of n. For example,  so m(283) is 0.45179.
so m(283) is 0.45179. 
 . Let’s say we wanted to multiply 2 by 4. We would take
. Let’s say we wanted to multiply 2 by 4. We would take 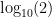 which is 0.301 and add
which is 0.301 and add 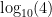 which is 0.602 to get 0.903. Then
which is 0.602 to get 0.903. Then  which is our answer. In order for this method to work, the logarithms of the numbers must be evenly spaced around the dial, not the numbers themselves (since we are adding the logarithms). We can use a circular slide rule to multiply numbers >10 as well, we just wrap around and adjust the position of the decimal point.
which is our answer. In order for this method to work, the logarithms of the numbers must be evenly spaced around the dial, not the numbers themselves (since we are adding the logarithms). We can use a circular slide rule to multiply numbers >10 as well, we just wrap around and adjust the position of the decimal point.
 to $latex\log_{10}(2)$ and the overall circumference of the circle is 1. Generalizing, the probability of having a first digit d is
to $latex\log_{10}(2)$ and the overall circumference of the circle is 1. Generalizing, the probability of having a first digit d is  . This is, of course, Benford’s Law!
. This is, of course, Benford’s Law!
 of the constant).
of the constant).  . The only distribution that doesn’t change when this operation is applied (regardless of the value of
. The only distribution that doesn’t change when this operation is applied (regardless of the value of 

 .
.  . The probability of a number having a second digit of 3 is the sum of the probabilities that the number starts with 13, 23, 33, …, and 93. So the probability that our second digit will be 3 is
. The probability of a number having a second digit of 3 is the sum of the probabilities that the number starts with 13, 23, 33, …, and 93. So the probability that our second digit will be 3 is  . This is approximately 0.104, so there is a 10.4% chance of having a 3 as the second digit in a dataset. If digits were distributed purely randomly there would be a 10% chance (remember we have 0 as a possible digit now). Repeating the process with all 10 digits, we find that the distribution of second digits is as seen below.
. This is approximately 0.104, so there is a 10.4% chance of having a 3 as the second digit in a dataset. If digits were distributed purely randomly there would be a 10% chance (remember we have 0 as a possible digit now). Repeating the process with all 10 digits, we find that the distribution of second digits is as seen below. 




 . Now our equivalence relation on fractions will be as follows (the ~ indicates equivalence relation):
. Now our equivalence relation on fractions will be as follows (the ~ indicates equivalence relation): 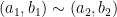 if and only if
if and only if 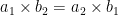 (the = sign represents standard equality). This makes sense because we can “cross-multiply” with fractions and preserve equality. Now that we have defined an equivalence relation, an example of an equivalence class for fractions would be all the fractions “equal” to (1, 2) such as (2, 4), (3, 6), (18,36), (510, 1020). These pairs of numbers are not really equal (we wouldn’t say (1,2) = (18, 36)) but with the correct equivalence relation defined, we can put them in the same equivalence class. Going into detail about the reflexivity, symmetry, and transitivity properties that any equivalence relation must have is a bit out of scope for this post, but I will give quick definitions here:
(the = sign represents standard equality). This makes sense because we can “cross-multiply” with fractions and preserve equality. Now that we have defined an equivalence relation, an example of an equivalence class for fractions would be all the fractions “equal” to (1, 2) such as (2, 4), (3, 6), (18,36), (510, 1020). These pairs of numbers are not really equal (we wouldn’t say (1,2) = (18, 36)) but with the correct equivalence relation defined, we can put them in the same equivalence class. Going into detail about the reflexivity, symmetry, and transitivity properties that any equivalence relation must have is a bit out of scope for this post, but I will give quick definitions here:
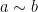 then
then 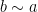
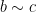 then
then 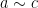
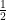 getting the answer right?
getting the answer right?



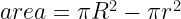
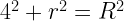
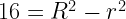
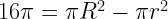
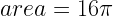

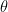 of horizontal, it will pass through the smaller circle. The total range of angles possible is 180 degrees and only chords passing through 2
of horizontal, it will pass through the smaller circle. The total range of angles possible is 180 degrees and only chords passing through 2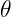 of this range pass through the center circle so
of this range pass through the center circle so 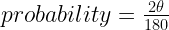 .
.

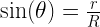
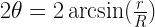
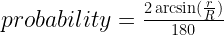

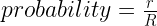
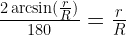 must be a mathematical identity. But if you plug in some numbers, say R = 15 and r = 3, you realize that these are most definitely not equal.
must be a mathematical identity. But if you plug in some numbers, say R = 15 and r = 3, you realize that these are most definitely not equal.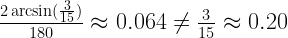


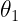 and
and 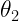 between 0 and 360 degrees.
between 0 and 360 degrees.












 meters per second at the perimeter to zero meters per second at O.
meters per second at the perimeter to zero meters per second at O.

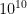 galaxies in the known universe. Assuming that each of these contains
galaxies in the known universe. Assuming that each of these contains  , as does our own galaxy, and that each of these stars is orbited by a mere ten other objects (planets, their moons, comets, asteroids, and small bits of rock or ice—any semi-spherical body will do), there are approximately
, as does our own galaxy, and that each of these stars is orbited by a mere ten other objects (planets, their moons, comets, asteroids, and small bits of rock or ice—any semi-spherical body will do), there are approximately  objects in the universe to choose from. The probability that any one of them, including Earth, is the preferred body is only
objects in the universe to choose from. The probability that any one of them, including Earth, is the preferred body is only 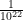 , which is vanishingly close to zero. Moreover, there is no reason why the inversion must be done in relation to a physical body at all. It is equally plausible to simply perform the inversion around an arbitrarily chosen spherical region of space, in which case the choice of regions and spheres is limitless. Regardless of which sphere we choose, if it is anything other than Earth, our planet becomes even smaller and less significant than ever after performing the necessary perspective transformation. We would be a minuscule speck, probably less than a fraction of a millimeter wide, floating near the center of some hollow celestial body.
, which is vanishingly close to zero. Moreover, there is no reason why the inversion must be done in relation to a physical body at all. It is equally plausible to simply perform the inversion around an arbitrarily chosen spherical region of space, in which case the choice of regions and spheres is limitless. Regardless of which sphere we choose, if it is anything other than Earth, our planet becomes even smaller and less significant than ever after performing the necessary perspective transformation. We would be a minuscule speck, probably less than a fraction of a millimeter wide, floating near the center of some hollow celestial body.

 .
.
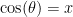
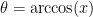
 is the size of the angle in which the needle can fall and intersect the line, and the total angle is 180 degrees or
is the size of the angle in which the needle can fall and intersect the line, and the total angle is 180 degrees or  radians. The probability of crossing the line for each value of x is therefore
radians. The probability of crossing the line for each value of x is therefore  . Since we need to add these probabilities for each possible value of
. Since we need to add these probabilities for each possible value of  , we integrate this function from 0 to 1.
, we integrate this function from 0 to 1.
 We can use the integral of
We can use the integral of 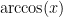 , see proof
, see proof 
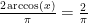
 or about 0.64.
or about 0.64.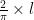 where
where 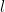 is the length of the line or curve.
is the length of the line or curve.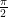 and
and 







 Isometric Solution:
Isometric Solution: Hopefully you were able to understand the drawings and figure out the solution!
Hopefully you were able to understand the drawings and figure out the solution!




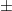 0.1
0.1
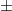 0.2 and an expected error of 0 (because the positive and negative error cancels out). But then somebody brought up the point that Christina’s measurements could “cancel out” if one was positive and the other was negative. Christina’s two measurements can combine to have zero error in multiple ways (for example, an error of +0.05 and then -0.05) while Alice’s measurement can only be error-free if he randomly gets that exact value. So Christina’s measurement must be better than Alice’s. This is actually the correct answer but this line of reasoning isn’t particularly helpful for figuring out specifics. How much better is Christina’s measurement? What if each of her measurements had an error of 0.175? How would having a normally distributed range of errors (rather than randomly distributed) affect the results? To answer these questions we need a mathematical solution to the problem.
0.2 and an expected error of 0 (because the positive and negative error cancels out). But then somebody brought up the point that Christina’s measurements could “cancel out” if one was positive and the other was negative. Christina’s two measurements can combine to have zero error in multiple ways (for example, an error of +0.05 and then -0.05) while Alice’s measurement can only be error-free if he randomly gets that exact value. So Christina’s measurement must be better than Alice’s. This is actually the correct answer but this line of reasoning isn’t particularly helpful for figuring out specifics. How much better is Christina’s measurement? What if each of her measurements had an error of 0.175? How would having a normally distributed range of errors (rather than randomly distributed) affect the results? To answer these questions we need a mathematical solution to the problem. randomly such that
randomly such that 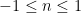 (I’m using 1 instead of 0.1 because I prefer to work with whole numbers and it doesn’t really make a difference)
(I’m using 1 instead of 0.1 because I prefer to work with whole numbers and it doesn’t really make a difference) with the same constraints.
with the same constraints.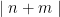 and compare to the expected value of
and compare to the expected value of 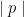 where p is randomly chosen such that
where p is randomly chosen such that 
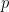 has an even probability distribution, all we need to show is that
has an even probability distribution, all we need to show is that 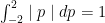 .
.
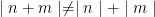 . We can apply the same process we used above but we have to graph in 3 dimensions because we now have an additional variable. Put n on the x axis, m on the z-axis, and the error on the y-axis. The function
. We can apply the same process we used above but we have to graph in 3 dimensions because we now have an additional variable. Put n on the x axis, m on the z-axis, and the error on the y-axis. The function 
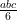 where a, b, and c are the lengths of the sides that from the right angle).
where a, b, and c are the lengths of the sides that from the right angle).


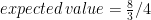 (4 is the area of the base of the cube)
(4 is the area of the base of the cube)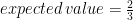
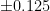 while her second was only accurate to within
while her second was only accurate to within 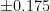 ) by drawing distorted tetrahedrons and calculating their volumes. But what if Christina took 3 measurements? Or 10? There is no way we can imagine and calculate volumes in 11 dimensional space. To do this problem, we have to recognize that what we just did above was calculate a double integral.
) by drawing distorted tetrahedrons and calculating their volumes. But what if Christina took 3 measurements? Or 10? There is no way we can imagine and calculate volumes in 11 dimensional space. To do this problem, we have to recognize that what we just did above was calculate a double integral.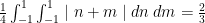
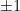 , we would simply take the triple integral. The number in front would change to
, we would simply take the triple integral. The number in front would change to 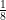 as well. Why? Because that number represents the probability distribution function for the individual errors. When there was just one randomly selected variable such that
as well. Why? Because that number represents the probability distribution function for the individual errors. When there was just one randomly selected variable such that  since the distribution function of p looked like a horizontal line through (0,
since the distribution function of p looked like a horizontal line through (0,  ) and
) and 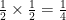 . This also answers the question of what happens when the probability distribution of the error is a normal distribution, you just plug the Gaussian into your integral before calculating. The calculus gets quite messy at that point, however, so I’m not going to do an example.
. This also answers the question of what happens when the probability distribution of the error is a normal distribution, you just plug the Gaussian into your integral before calculating. The calculus gets quite messy at that point, however, so I’m not going to do an example. is the probability distribution function for x, we get:
is the probability distribution function for x, we get: