
When you send an email, do you ever wonder how that data makes its way from your phone or computer to whoever you are sending it to? This question gets to the core of how the internet works, which in all its power and magic, is essentially a data transfer system. But it is a ridiculously huge data transfer system – it’s estimated that global internet traffic is around 122,000 petabytes per month (for reference, a petabyte is about 10,000 4k movies worth of data). This term, I took a class called Communication Networks that focused on understanding the protocols that make the internet work under the hood. I found a good layperson’s overview of some of these topics in this Medium article, in case you’re also interested. Personally, I was particularly fascinated by routing protocols, which determine the paths through the network that packets (bits of data) take to make it to their appropriate destinations.
What are Routing Protocols?
First, a bit of background is needed to understand routing protocols. There exists some collection of hosts (people’s personal devices) which are the sources and destinations for the data packets. A limited number of hosts can connect to a single router – which is a device whose job it is to get packets to their correct destination. Each router is also connected to a limited number of other routers. All together, these connections form a network of millions of routers that connect billions of hosts.

Now, the problem that routing protocols try to solve can be formulated as follows: When host A sends a packet to host B, what path should that packet take to get to B as fast as possible? Once these paths are decided for every pair of hosts, the routers ensure that packets (which are tagged with their destination) actually travel along these routes. Each router has a routing table which tells it which one of its neighbors to route each packet to (based on the packet’s destination). Routing tables fully determine the path that every packet in the network will take, so we can reformulate our problem as: What should the routing tables be so that packets get to their destinations as fast as possible?
It remains to ask: What makes a certain path fast or slow? Initially you might think that it’s solely based on the number of links on the path (more links = slower) and to some extent this is true. However, it is also true that increased traffic along a connection makes it slower due to queuing delay. You can think of queueing delay as the time the packets have to stand in line before being sent along a busy link. This adds complexity to the problem, as the choice of routing tables affects how many packets are sent along a particular link, and therefore affects the average travel time of the packets (a.k.a. the average packet delay). This means that a good routing protocol will make trade-offs between choosing the shortest paths and avoiding routing packets along highly trafficked links.
Dynamic Shortest Paths Routing
The routing protocol that is actually used in the internet is a variation of dynamic shortest paths routing. Shortest paths is a bit of a misnomer, as it is not actually shortest paths routing but fastest paths routing. At every timestep, the protocol involves constructing the graph consisting of all the routers in the network and their connections, and assigning each directed edge a weight. This weight is the packet delay along the link calculated using the current routing table and the data traffic from the previous timestep. Note that both of these are required to calculate the total traffic along the link, and therefore the packet delay.
Once this graph is constructed, an algorithm like Floyd-Warshall is used to calculate all-pairs shortest paths for the weighted graph. This corresponds to all-pairs fastest paths for the network, since the weight on each edge is the time to travel along that edge. So minimizing the weighted length of the path from A to B minimizes the travel time of a packet going from A to B. The routing tables in the network are then updated to match the shortest paths found by Floyd-Warshall.

The ‘dynamic’ in the name of this protocol comes from the fact that it updates the routing tables at every timestep based on the traffic of the previous timestep. This means that it can naturally accommodate traffic distributions that change over time. We would hope that under stationary traffic distributions, dynamic shortest paths routing would eventually converge, however this is not the case. In fact, a major disadvantage of dynamic shortest paths routing is that the routing tables can oscillate wildly between timesteps. This behavior comes from the fact that the algorithm generally chooses to use links that were lightly trafficked (and therefore fast) in the previous timestep, but does not consider that this choice will cause those very links to now be heavily trafficked (and therefore slow). The variants on dynamic shortest paths routing that are used in practice exist mainly to address this problem. If you would like to know more about these variants, an interesting paper on preventing oscillations in routing tables can be found here.
Visualizations (Shortest Paths)
Code on Github
Probabilistic Routing
An interesting alternative to the routing protocols used in practice can be found in the paper “A Minimum Delay Routing Algorithm Using Distributed Computation” by Robert Gallagher (1977). We can consider the routing tables we have talked about so far to be deterministic: once the routing table is fixed, all packets traveling from A to B follow the same path. Gallagher proposes routing tables that we will call ‘probabilistic’, meaning that all traffic traveling from A to B does not necessarily take the same route (even within a timestep). Given a packet at router A destined for B, the packet’s next location is drawn from a probability distribution over neighbors of A. This probability distribution is defined in the routing table for A.
The benefit of this formulation of routing tables is that it allows more flexibility in dividing traffic evenly across the network, and therefore allows for less packet delay. In fact, Gallagher gives a protocol for updating probabilistic routing tables that he proves always converges to the minimal average packet delay given stationary traffic distributions. This means that it’s relatively easy to make probabilistic routing optimal! However, the trade-off is that probabilistic routing tables are more complicated, since implementing them requires every router to be able to sample from a probability distribution.
As our project for Communication Networks, we implemented Gallagher’s protocol and checked that it converged to the optimal routing tables by also performing numerical minimization of the average packet delay (using scipy). Our code for this project can be found at our GitHub. Interestingly, we found a small network (only 4 nodes!) where the best probabilistic routing table significantly outperforms the best deterministic routing table. This means that using probabilistic routing tables could prove worthwhile in networks where minimizing packet delay is very important and simple network design is less of a consideration.
Visualizations (Gallagher)
Code on Github



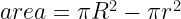
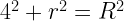
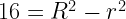
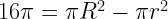
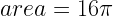

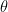 of horizontal, it will pass through the smaller circle. The total range of angles possible is 180 degrees and only chords passing through 2
of horizontal, it will pass through the smaller circle. The total range of angles possible is 180 degrees and only chords passing through 2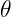 of this range pass through the center circle so
of this range pass through the center circle so 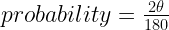 .
.

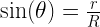
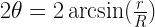
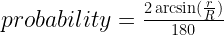

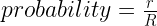
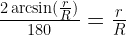 must be a mathematical identity. But if you plug in some numbers, say R = 15 and r = 3, you realize that these are most definitely not equal.
must be a mathematical identity. But if you plug in some numbers, say R = 15 and r = 3, you realize that these are most definitely not equal.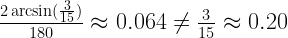


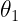 and
and 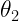 between 0 and 360 degrees.
between 0 and 360 degrees.




